Tag
Eval
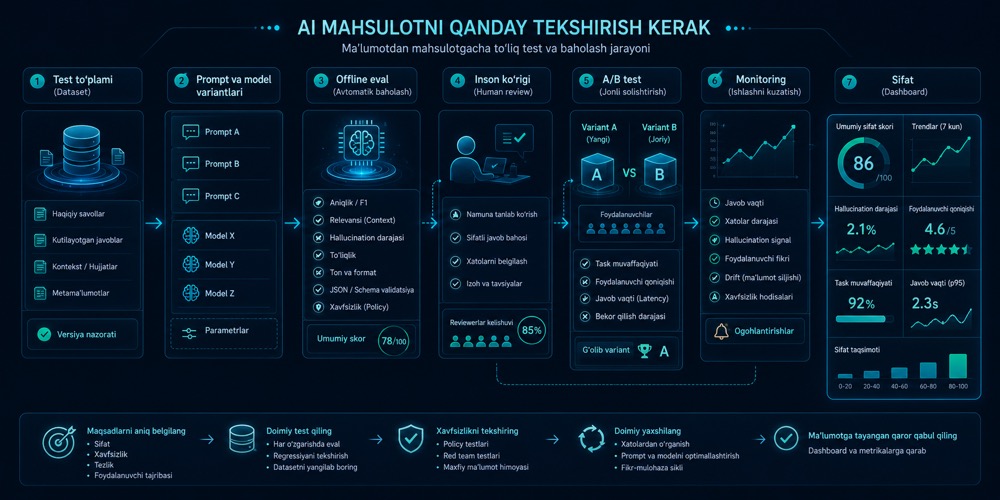
AI mahsulotni qanday tekshirish kerak
AI mahsulot sifati faqat model javobi bilan o‘lchanmaydi. Offline eval, inson review, A/B test va monitoring birga ishlaganda regressiya, xavfsizlik va foydalanuvchi tajribasi aniqroq boshqariladi.
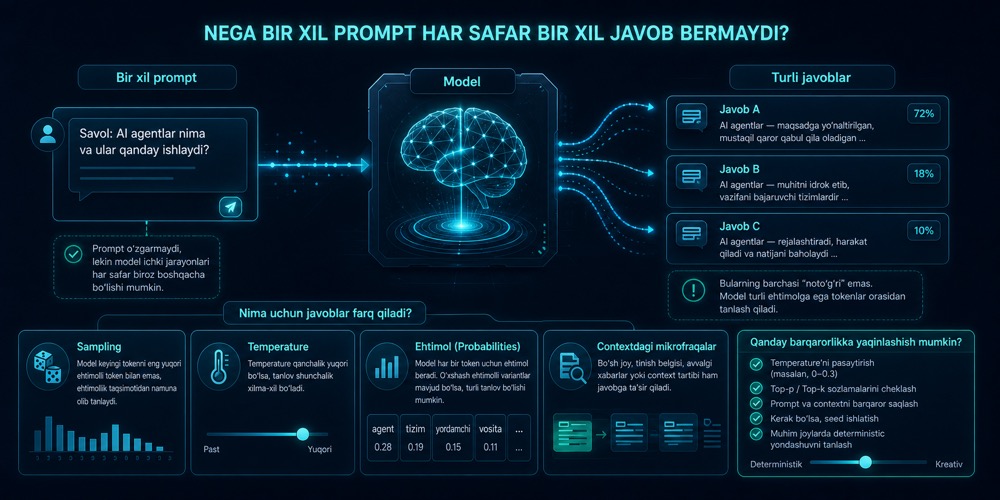
Nega bir xil prompt har safar bir xil javob bermaydi
LLM javobi ko‘pincha ehtimollarga tayangan holda yaratiladi, shu sabab bir xil prompt turli natija berishi mumkin. Temperature, sampling va contextdagi mayda farqlar chiqishning barqarorligiga ta’sir qiladi.
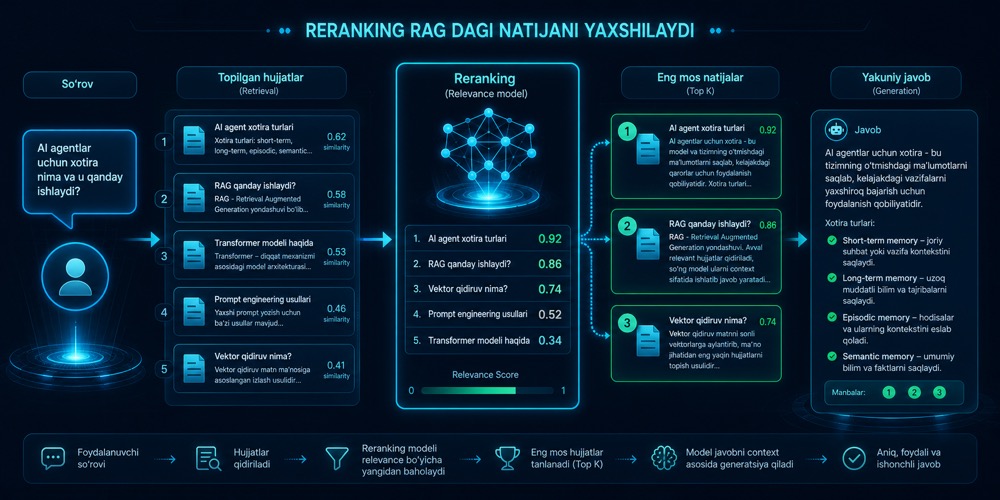
Reranking va uning RAGdagi foydasi
RAG tizimida birinchi topilgan hujjatlar har doim eng foydali bo‘lavermaydi. Reranking topilgan natijalarni qayta saralab, modelga aniqroq va foydaliroq context yuborishga yordam beradi.
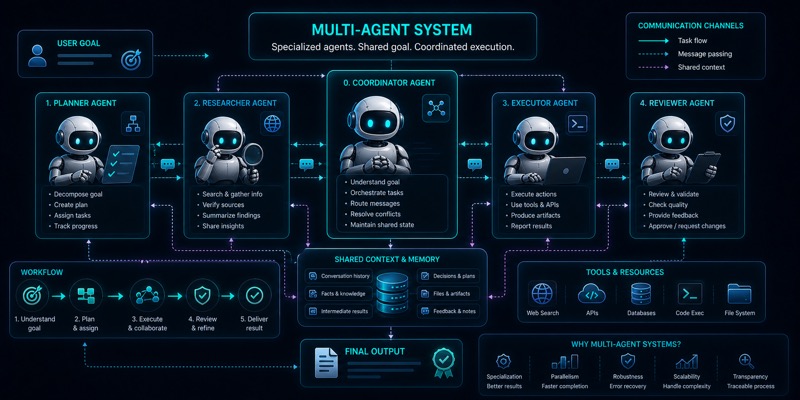
Multi-agent system qachon kerak bo‘ladi
Murakkab workflow’larda bitta agentga hamma rolni berish doim ham yaxshi natija bermaydi. Multi-agent yondashuv rollarni ajratadi, lekin koordinatsiya, kechikish va xato nuqtalarini ham ko‘paytiradi.
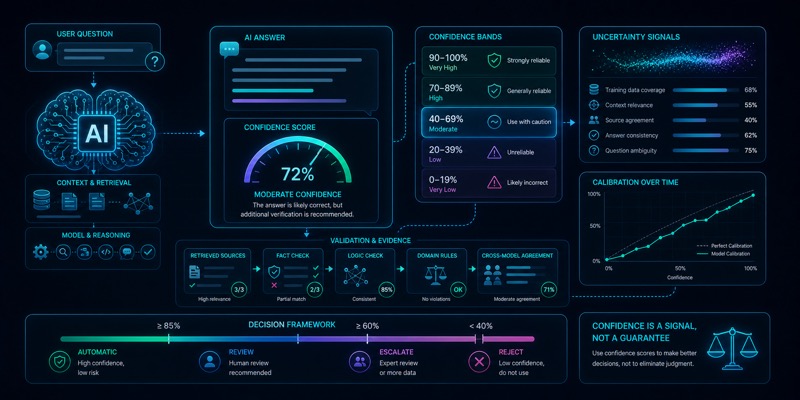
Confidence score nima va unga qanchalik ishonish mumkin
Confidence score foydali signal bo‘lishi mumkin, lekin uni haqiqat mezoni deb qabul qilish xavfli. Ishonch darajasi eval, validation va inson nazorati bilan birga talqin qilinganda ancha foydaliroq bo‘ladi.

Guardrails: agentga qayerda to‘siq qo‘yiladi
Guardrails agentni foydali chegarada ushlab turadi: prompt, tool, permission, output va inson approvali darajasida xavfli harakatlar to‘xtatiladi.

Structured outputni tekshirish: schema validation amalda
Structured output foydali bo‘lishi uchun model qaytargan JSON yoki obyekt faqat ko‘rinishda emas, schema bo‘yicha ham tekshirilishi kerak.
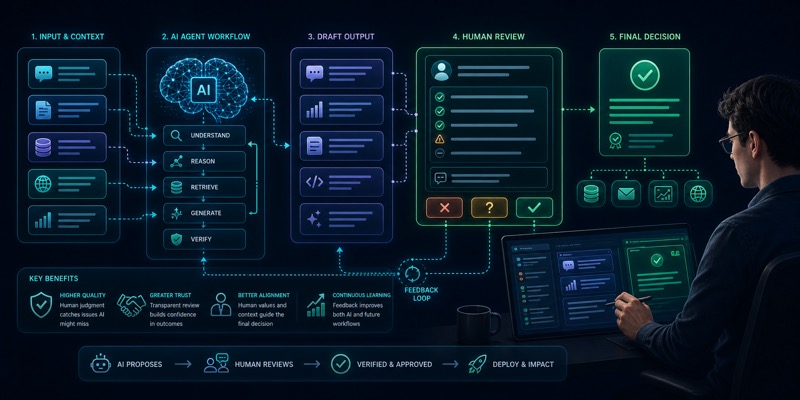
Human-in-the-loop tushunchasi va u qachon kerak bo'ladi
AI mahsulotda hamma qarorni avtomatlashtirish shart emas. Human-in-the-loop yondashuvi xavfli yoki noaniq qadamlarni inson tasdig‘i bilan bog‘lab, sifat va ishonchni oshiradi.
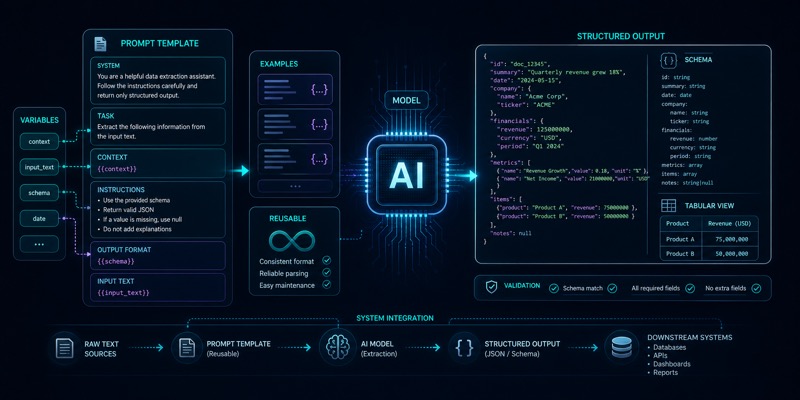
Prompt template va structured outputning farqi
Prompt template va structured output AI funksiyasini “qo‘lda yozilgan matn”dan boshqariladigan mahsulot qatlamiga aylantiradi. Ular format, validation va qayta ishlatishni barqarorroq qiladi.

Observability: AI agent ichida nima bo‘layotganini qanday ko‘ramiz
AI agent xato qilganda muammo promptdami, retrieval’dami, tool call’dami yoki ruxsat qatlamidami - buni ko‘rish kerak. Observability agent ichidagi qadamlarni izchil kuzatishga yordam beradi.

Junior dasturchi AI davrida nimani o‘rganishi kerak
AI kod yozishni osonlashtiryapti, lekin bu junior dasturchiga fundamental bilim kerak emas degani emas. Aksincha, kodni tushunish, tekshirish, debug qilish va to‘g‘ri savol berish qobiliyati yanada muhim bo‘lib qoldi.

AI javobini baholash: eval qanday ishlaydi
AI javobini baholash sezgi bilan emas, oldindan belgilangan mezonlar bilan aniqroq bo‘ladi. Eval prompt, model, retrieval va mahsulot sifatini solishtirish uchun kerakli o‘lchov beradi.
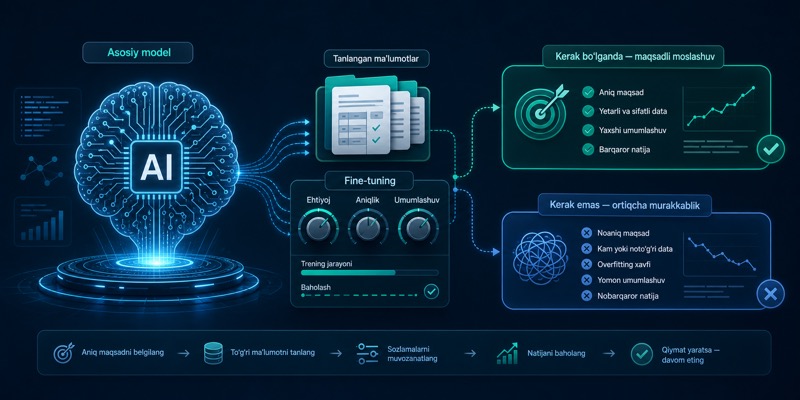
Fine-tuning qachon kerak, qachon ortiqcha
Fine-tuning har doim birinchi yechim emas: ko‘p holatda yaxshi context, RAG yoki prompt yetarli bo‘ladi. Modelni moslashtirish kerak bo‘ladigan vaziyatlar va ortiqcha murakkablik chegarasi ajratiladi.
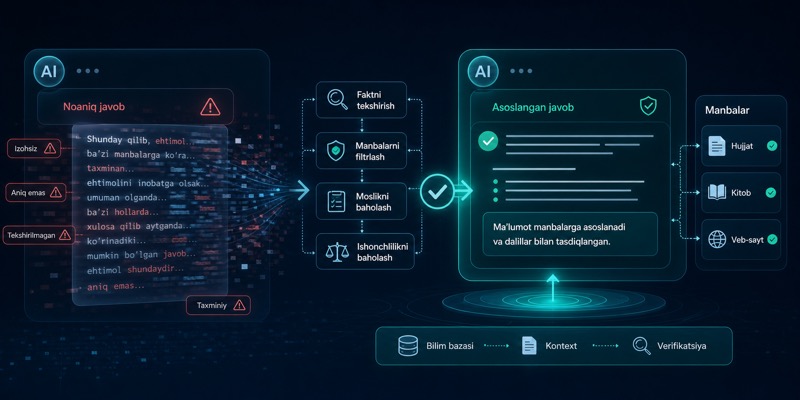
Hallucinationni kamaytirish usullari
AI model ba’zan ishonchli ohangda noto‘g‘ri gapiradi. Bu holat hallucination deyiladi. Maqolada hallucination qayerdan kelishini va uni prompt, context, RAG, tool use hamda validation orqali qanday kamaytirish mumkinligini ko‘rib chiqaman.

AI atamalari: Context, Agent, Harness, Model va boshqalar
AI atamalari chalkash ko‘rinsa, ularni alohida yodlashdan ko‘ra amaliy vazifada ko‘rish osonroq. Context, prompt, model, token, agent, RAG va fine-tuning kabi so‘zlar sodda misollar bilan tartiblanadi.
AI’ni bunday o‘rganmang: boshlovchilar uchun to‘g‘ri yo‘nalish
AI’ni o‘rganishni ko‘pchilik noto‘g‘ri joydan boshlaydi: faqat kurs yig‘ish, trend quvish, model nomlarini yodlash va amaliyotsiz nazariya bilan vaqt o‘tkazish. Boshlovchi uchun eng to‘g‘ri yo‘l esa sodda: bitta yo‘nalish tanlash, kichik loyiha qilish va har hafta natija chiqarish.