AI bilan ishlaganda foydalanuvchini eng ko‘p chalg‘itadigan narsa - modelning xato qilishi emas, balki xato gapni ishonch bilan aytishi. Ya’ni javobning ohangi juda aniq, lekin ichidagi fakt noto‘g‘ri bo‘lishi mumkin. Shu holat odatda hallucinationModel ishonchli gapirgandek ko‘rinsa ham, noto‘g‘ri yoki uydirma ma’lumot chiqarib yuboradigan holat. deb ataladi.
Bu ayniqsa xavfli, chunki foydalanuvchi xato javobni darrov sezmasligi mumkin. Kodda uydirma API yozib beradi, huquqiy matnda yo‘q norma keltiradi, biznes savolda mavjud bo‘lmagan raqamni ishonch bilan aytadi. Muammo shundaki, model “bilmayman” deyishdan ko‘ra, ko‘pincha ehtimoliy javob qurishga moyil bo‘ladi.
HallucinationModel ishonchli gapirgandek ko‘rinsa ham, noto‘g‘ri yoki uydirma ma’lumot chiqarib yuboradigan holat. nima o‘zi?
HallucinationModel ishonchli gapirgandek ko‘rinsa ham, noto‘g‘ri yoki uydirma ma’lumot chiqarib yuboradigan holat. - bu modelning mavjud bo‘lmagan, noto‘g‘ri yoki yetarli asosga ega bo‘lmagan ma’lumotni javob sifatida chiqarishi. Bu faqat “yolg‘on gapirdi” degani emas. Ba’zan model noto‘g‘ri manba keltiradi, ba’zan sana yoki raqamni adashtiradi, ba’zan esa foydalanuvchi so‘ramagan taxminni fakt sifatida yozadi.
Shuni tushunish kerak: model ma’lumotlar bazasi emas, u patternlar asosida keyingi tokenni taxmin qiladi. Shuning uchun javob mantiqan chiroyli bo‘lishi mumkin, lekin faktual jihatdan noto‘g‘ri chiqishi ehtimoli bor.
HallucinationModel ishonchli gapirgandek ko‘rinsa ham, noto‘g‘ri yoki uydirma ma’lumot chiqarib yuboradigan holat. qayerdan keladi?
- ContextModelga shu paytda berilgan foydali ma’lumotlar to‘plami: qoida, hujjat, oldingi xabarlar va vazifa tavsifi. yetishmasa.
- PromptModelga berilgan ko‘rsatma yoki topshiriq matni. Javob sifati ko‘pincha shu kirishga bog‘liq bo‘ladi. noaniq bo‘lsa.
- Modeldan aslida unda bo‘lmagan bilim talab qilinsa.
- Uzun javob yozishga majburlanganda model bo‘sh joyni taxmin bilan to‘ldirsa.
- Tashqi manba bilan tekshirish qatlami bo‘lmasa.
Ko‘p hollarda asosiy sabab bitta: modelga aniq tayanch berilmagan bo‘ladi. U esa bo‘sh joyni “eng mantiqli ko‘rinadigan” javob bilan to‘ldiradi.
1. Promptni toraytirish
Juda umumiy savollar hallucinationModel ishonchli gapirgandek ko‘rinsa ham, noto‘g‘ri yoki uydirma ma’lumot chiqarib yuboradigan holat. ehtimolini oshiradi. “Bu haqda hammasini aytib ber” degan so‘rov ko‘pincha modelni keng taxmin qilishga undaydi. Savol qancha aniq bo‘lsa, modelning adashishi shuncha kamayadi.
Masalan, “OAuth haqida yoz”dan ko‘ra, “OAuth 2.0 authorization code flow’ni 5 punktda tushuntir” ancha xavfsizroq. Modelga chegarani siz berishingiz kerak. Bu yerda promptdan ko‘ra context ko‘proq yordam beradi.
2. Contextni kuchaytirish
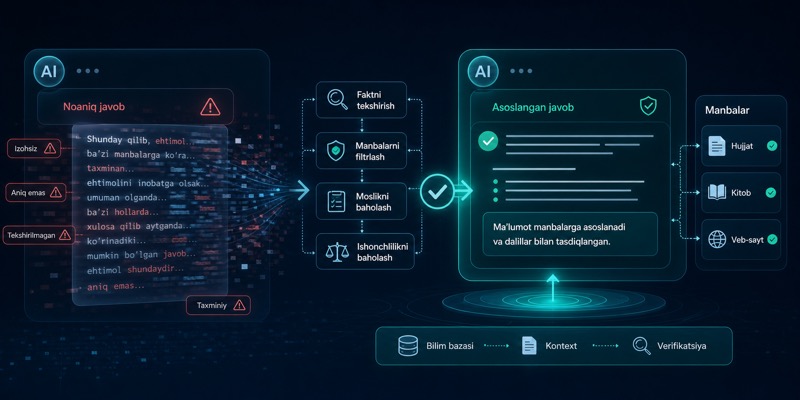
Hallucinationni kamaytirishning eng kuchli usullaridan biri - modelga kerakli contextni oldindan berish. Hujjat, policy, kod parchasi, jadval, API spec yoki oldingi xabarlar bo‘lsa, javob ancha grounded bo‘ladi.
Agar foydalanuvchi “mijozga javob yoz” desa, modelga faqat topshiriq emas, mijoz xati, mahsulot tavsifi va ohang qoidasi ham kerak bo‘ladi. Shunda u kamroq taxmin qiladi.
3. RAGRetrieval-Augmented Generation qisqartmasi. Model javob berishdan oldin tashqi manbadan kerakli ma’lumot olib keladi. yoki manbaga tayangan javob
Agar javob tashqi hujjatga tayangan bo‘lishi kerak bo‘lsa, RAG juda foydali bo‘lishi mumkin. Modelga kerakli parcha retrieval orqali beriladi va u shu asosda javob yozadi. Bu ayniqsa ichki knowledge base, support docs, policy va qonun hujjatlarida foydali.
Lekin RAGRetrieval-Augmented Generation qisqartmasi. Model javob berishdan oldin tashqi manbadan kerakli ma’lumot olib keladi. ham mo‘jiza emas. Noto‘g‘ri chunk yoki yomon retrieval bo‘lsa, model noto‘g‘ri kontekstga tayangan holda yana xato qilishi mumkin. Demak muammo faqat modelda emas, retrieval qatlamida ham bo‘lishi mumkin.
4. Tool useModel yoki agentning brauzer, API, terminal, fayl tizimi yoki boshqa tashqi vositalardan foydalanishi. va tekshirish
Model o‘zi bilmagan narsani tashqi tool orqali tekshirib olishi mumkin bo‘lsa, hallucinationModel ishonchli gapirgandek ko‘rinsa ham, noto‘g‘ri yoki uydirma ma’lumot chiqarib yuboradigan holat. ancha kamayadi. Masalan:
- web search orqali yangi faktni tekshirish,
- API orqali real ma’lumotni olish,
- kodni ishga tushirib natijani ko‘rish,
- database’dan aniq yozuvni o‘qish.
“Model yozdi” bilan “model tekshirib yozdi” o‘rtasida katta farq bor. Ayniqsa agentlarga yaqin workflow’larda bu juda muhim.
5. Format va cheklov berish
Ba’zan modelga “faqat berilgan hujjatga tayangan holda javob ber”, “bilmasang ayt”, “manba keltir”, “taxmin qilma” kabi cheklovlar berish foyda beradi. Bu hallucinationni nolga tushirmaydi, lekin modelning erkin taxmin qilish maydonini toraytiradi.
Masalan, quyidagi qoida foydali bo‘lishi mumkin: “Agar berilgan kontekstda javob bo‘lmasa, shuni aniq ayt va qo‘shimcha taxmin yozma.”
6. Insoniy review kerak bo‘ladigan joylar
Ba’zi mavzularda hallucinationModel ishonchli gapirgandek ko‘rinsa ham, noto‘g‘ri yoki uydirma ma’lumot chiqarib yuboradigan holat. narxi juda yuqori bo‘ladi: tibbiyot, huquq, moliya, xavfsizlik, ishlab chiqarish qarorlari. Bu joylarda AI javobi yakuniy hujjat emas, qoralama yoki yordamchi tahlil sifatida ko‘rilgani to‘g‘riroq.
Qisqasi, AI “birinchi versiya”ni tez tayyorlaydi. Lekin ayrim domenlarda oxirgi imzo baribir odamdan chiqishi kerak.
7. Evaluation qilish
Hallucinationni kamaytirish bir martalik ish emas. PromptModelga berilgan ko‘rsatma yoki topshiriq matni. Javob sifati ko‘pincha shu kirishga bog‘liq bo‘ladi. o‘zgardi, model o‘zgardi, retrieval o‘zgardi - natija ham o‘zgaradi. Shu sababli real savollar to‘plami bilan muntazam evaluation qilish kerak.
Masalan, 20-30 ta odatiy savol oling va tekshiring:
- javobda uydirma fakt bormi,
- manba bilan mos keladimi,
- formatga rioya qildimi,
- bilmagan joyda to‘xtadimi yoki taxmin qildimi.
Xulosa
HallucinationModel ishonchli gapirgandek ko‘rinsa ham, noto‘g‘ri yoki uydirma ma’lumot chiqarib yuboradigan holat. AI’ning eng muhim amaliy cheklovlaridan biri. Uni butunlay yo‘qotish qiyin, lekin sezilarli kamaytirish mumkin. Buning uchun aniq promptModelga berilgan ko‘rsatma yoki topshiriq matni. Javob sifati ko‘pincha shu kirishga bog‘liq bo‘ladi., kuchli contextModelga shu paytda berilgan foydali ma’lumotlar to‘plami: qoida, hujjat, oldingi xabarlar va vazifa tavsifi., to‘g‘ri retrieval, tool useModel yoki agentning brauzer, API, terminal, fayl tizimi yoki boshqa tashqi vositalardan foydalanishi., cheklovlar va muntazam evaluation birga ishlashi kerak.
Eng foydali yondashuv shuki: modelga ishonish emas, uni to‘g‘ri ish muhitiga qo‘yish. Shunda u kamroq taxmin qiladi, ko‘proq foyda beradi.