AI bilan ishlashni boshlagan odamlarning ko‘pi bir joyda fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. haqida eshitadi. Shunda tabiiy savol tug‘iladi: modelni o‘z vazifamga moslab qo‘ysam, hammasi ancha yaxshi ishlaydimi? Ba’zan ha. Lekin ko‘p hollarda javob - yo‘q. Avval AI’ni qanday o‘rganish va muammoni qanday ajratish kerakligini tushunish foydaliroq.
Fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. foydali instrument, lekin u birinchi qadam bo‘lishi shart emas. Ko‘p mahsulotlar uchun muammo modelda emas, balki topshiriqning noaniqligi, kontekst yetishmasligi yoki retrieval sifati yomonligida bo‘ladi.
Fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. nima?
Fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. - tayyor modelni sizning ma’lum vazifa, uslub yoki domeningizga yaqinlashtirish uchun qo‘shimcha o‘qitish. Bu modelni noldan yaratish emas, balki mavjud modelga qo‘shimcha yo‘nalish berishdir.
Masalan, modelni ma’lum javob formatiga o‘rgatish, tor domen terminlarini barqarorroq ishlatish yoki ma’lum uslubni saqlash uchun fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. kerak bo‘lishi mumkin.
Ko‘p hollarda avval nima qilish kerak?
- Promptni aniqlashtirish.
- Yaxshi contextModelga shu paytda berilgan foydali ma’lumotlar to‘plami: qoida, hujjat, oldingi xabarlar va vazifa tavsifi. berish.
- Relevant hujjatlarni retrieval orqali ulash.
- Output formatini qat’iy belgilash.
- Evaluation orqali haqiqiy muammoni topish.
Agar shu narsalar hali to‘g‘ri qilinmagan bo‘lsa, fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. ko‘pincha noto‘g‘ri joyga sarflangan kuch bo‘ladi. Ayniqsa contextModelga shu paytda berilgan foydali ma’lumotlar to‘plami: qoida, hujjat, oldingi xabarlar va vazifa tavsifi. masalasini tushunish uchun system prompt, user prompt va context farqini ajratib olish kerak.
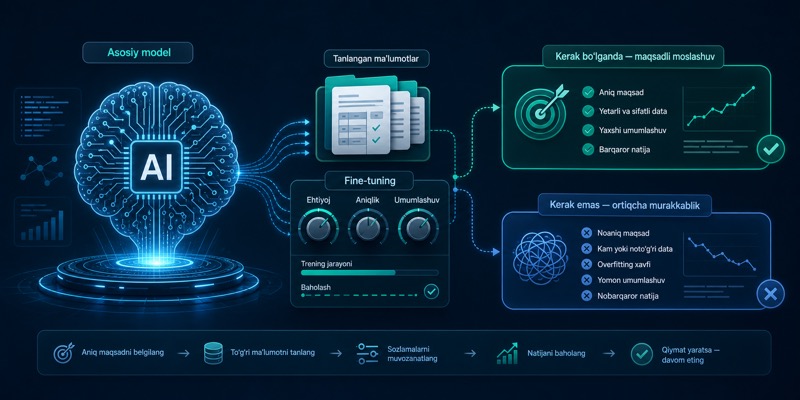
Qachon fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. kerak bo‘lishi mumkin?
- bir xil formatni juda barqaror qaytarish kerak bo‘lsa,
- maxsus domen tilini yaxshi ushlashi zarur bo‘lsa,
- ko‘p misolli tor vazifa doimiy takrorlansa,
- promptModelga berilgan ko‘rsatma yoki topshiriq matni. Javob sifati ko‘pincha shu kirishga bog‘liq bo‘ladi. juda murakkab bo‘lib ketib, uni model ichiga “singdirish” foydali bo‘lsa.
Masalan, ichki klassifikatsiya taski, aniq label’lar bilan extraction, maxsus yozish uslubi yoki qat’iy tuzilgan machine-readable output fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. uchun yaxshi kandidat bo‘lishi mumkin.
Qachon ortiqcha bo‘ladi?
- ma’lumot tez-tez yangilanib tursa,
- javob hujjatlarga tayangan bo‘lishi kerak bo‘lsa,
- muammo fakt yetishmasligida bo‘lsa,
- sizda sifatli training dataset bo‘lmasa.
Bunday holatda RAG yoki yaxshi contextModelga shu paytda berilgan foydali ma’lumotlar to‘plami: qoida, hujjat, oldingi xabarlar va vazifa tavsifi. ko‘proq foyda beradi. Fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. modelga yangi dolzarb faktlarni “doimiy xotira” sifatida berib qo‘ymaydi. U retrieval o‘rnini bosa olmaydi.
Fine-tuningning narxi va riski
Fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. faqat “modelni yaxshilash” emas. U bilan birga dataset tayyorlash, tozalash, label sifati, test to‘plami, qayta baholash va versiyalash keladi. Agar training ma’lumot yomon bo‘lsa, fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. natijani yaxshilash o‘rniga buzib qo‘yishi ham mumkin.
Shu sababli fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. oldidan savol berish kerak: biz haqiqatan model xulqini o‘zgartirmoqchimizmi, yoki shunchaki unga yaxshiroq ma’lumot berishimiz kerakmi?
Xulosa
Ko‘p holatda promptModelga berilgan ko‘rsatma yoki topshiriq matni. Javob sifati ko‘pincha shu kirishga bog‘liq bo‘ladi., contextModelga shu paytda berilgan foydali ma’lumotlar to‘plami: qoida, hujjat, oldingi xabarlar va vazifa tavsifi. va RAGRetrieval-Augmented Generation qisqartmasi. Model javob berishdan oldin tashqi manbadan kerakli ma’lumot olib keladi. bilan muammo hal bo‘ladi. Fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. esa odatda keyingi bosqich: qachonki siz muammoni aniq tushungan bo‘lsangiz, dataset tayyor bo‘lsa, eval bor bo‘lsa va yutuq aynan model xulqini o‘zgartirishdan kelayotgan bo‘lsa.
Qisqasi, har safar “fine-tuningModelni ma’lum uslub, domen yoki vazifaga yaqinlashtirish uchun qo‘shimcha ma’lumot bilan qayta moslash jarayoni. qilamiz” deyishdan oldin “muammo modeldami yoki ma’lumotdami?” deb so‘rash foydaliroq.