Tag
Token

Caveman nima va u AI agent token xarajatini qanday kamaytiradi?
Caveman - AI agentning javob uslubini qisqartirib token sarfini kamaytiradigan skill va plugin to‘plami. U ayniqsa Claude Code, Codex, Cursor va boshqa coding agentlarda ortiqcha gapni kesib, texnik mazmunni saqlab qoladi.
Context compression. Uzun kontekst qanday ixchamlashtiriladi
Modelga ko‘proq matn yuborish har doim yaxshiroq natija bermaydi. Context compression foydali signalni saqlab, keraksiz shovqinni qisqartirish orqali narx, tezlik va aniqlik o‘rtasidagi muvozanatni yaxshilaydi.

AI billingda eng ko‘p uchraydigan 5 yashirin xarajat
AI mahsulot qurayotganda ko‘pchilik model narxiga qaraydi, lekin invoice’ni shishiradigan omillar ko‘pincha boshqa joyda bo‘ladi. Ortiqcha kontekst, retry zanjiri, noto‘g‘ri routing va uzun output lar billingni sekin, lekin muntazam ravishda oshiradi.

Pullik AI obunasi arziydimi: qachon to‘lash kerak, qachon bepul variant yetadi?
AI mahsulotlardan foydalanayotgan ko‘p odam bitta joyda to‘xtaydi: pullik reja olamanmi, yo‘qmi? Savol oddiy ko‘rinadi, lekin javob faqat narxga qarab berilmaydi. Ko‘p hollarda asosiy savol bunday bo‘lishi kerak: bu obuna menga vaqt tejayaptimi, yaxshiroq workflow berayaptimi va bepul variantda yo‘q real ustunlik bormi?
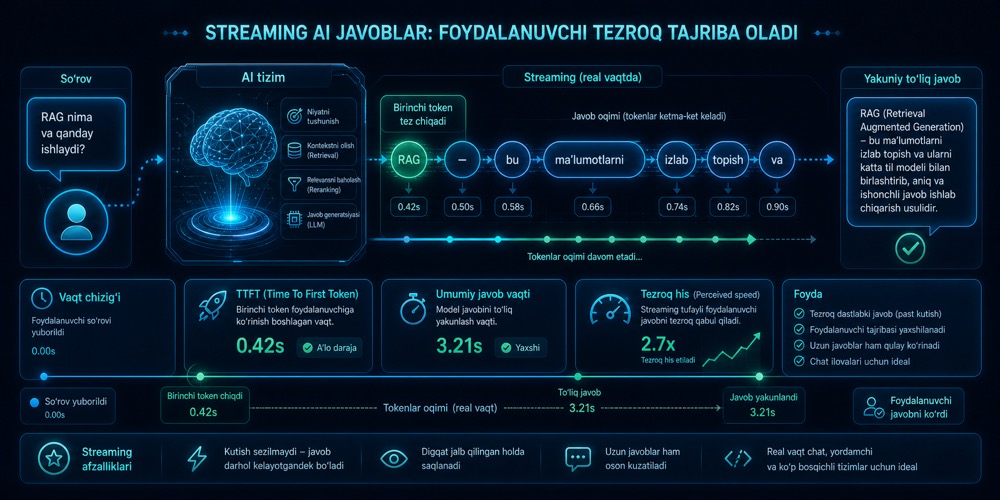
Streaming nima va u AI mahsulotda nega muhim
AI javobi tayyor bo‘lib bo‘lgach emas, yozilish jarayonida ko‘rina boshlasa, foydalanuvchi tizimni ancha tez qabul qiladi. Streaming time-to-first-tokenni pasaytirib, seziladigan kutishni kamaytiradi.
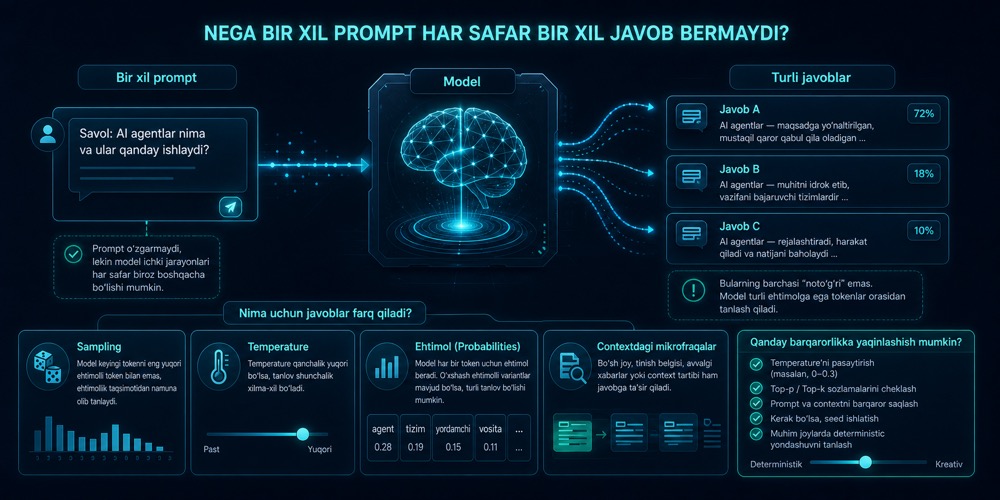
Nega bir xil prompt har safar bir xil javob bermaydi
LLM javobi ko‘pincha ehtimollarga tayangan holda yaratiladi, shu sabab bir xil prompt turli natija berishi mumkin. Temperature, sampling va contextdagi mayda farqlar chiqishning barqarorligiga ta’sir qiladi.
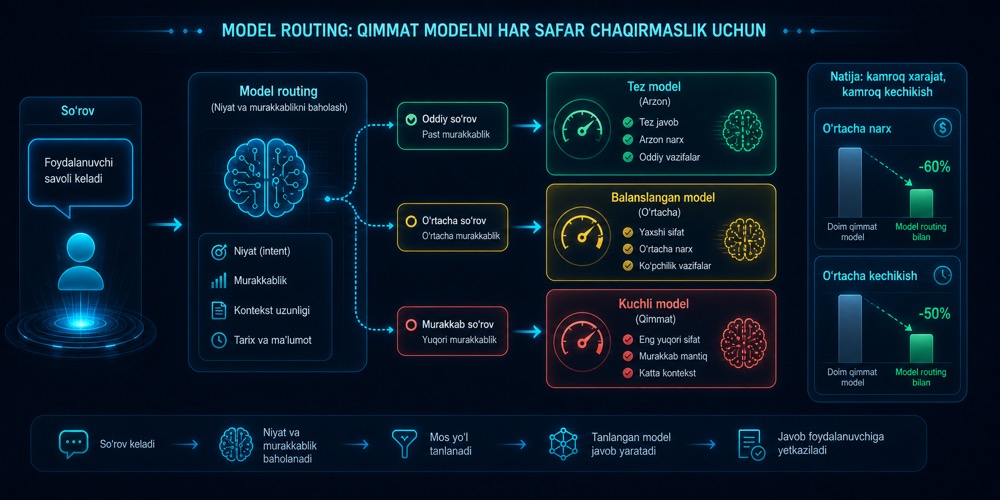
Model routing nima va qimmat modelni har safar chaqirmaslik uchun nima qilish kerak
Har bir so‘rov uchun eng katta modelni ishlatish odatda eng yaxshi arxitektura emas. Model routing vazifa murakkabligiga qarab tez, arzon va kuchli modellar o‘rtasida tanlov qilishga yordam beradi.
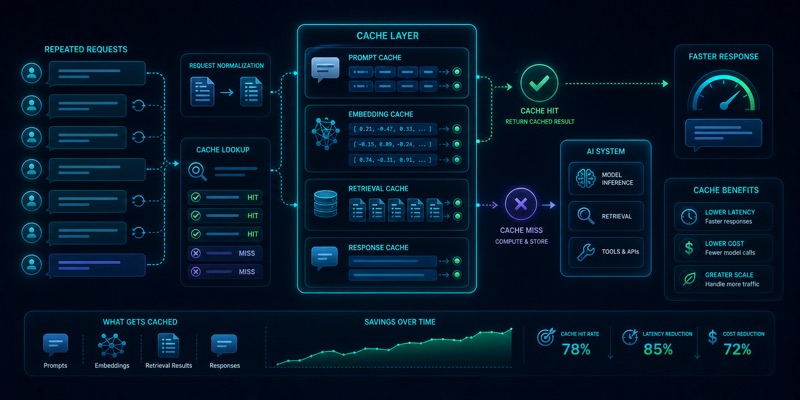
Caching: AI xarajatini qanday kamaytiradi
Bir xil prompt, retrieval yoki model javobini qayta hisoblash AI mahsulotni sekin va qimmat qiladi. Caching takror ishlarni kamaytirib, xarajat va kechikishni nazorat qilishga yordam beradi.

Latency: AI mahsulotda nega muhim
AI mahsulotda javob sekin chiqsa, muammo faqat modelda bo‘lmasligi mumkin. Kechikish token hajmi, retrieval, tool call, cache va tashqi servislar zanjirida paydo bo‘ladi.

Context window: amalda nimani cheklaydi
Context window model bir urinishda qancha ma’lumotni ko‘ra olishini belgilaydi. Bu xotira emas; ortiqcha context narx, diqqat va kechikishga bevosita ta’sir qiladi.
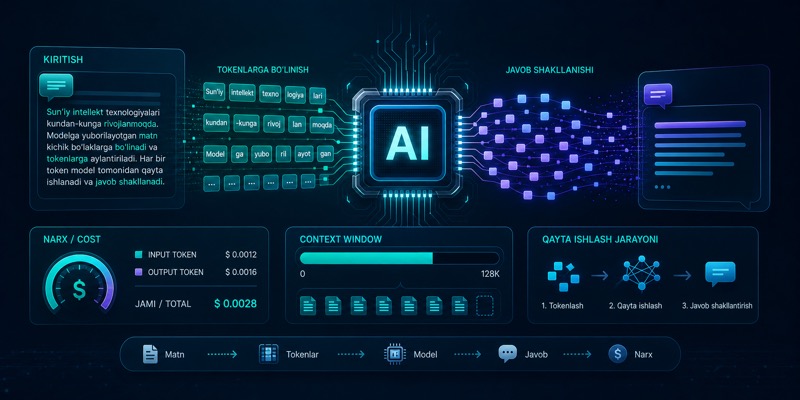
Nega AI narxi tokenga bog‘liq
AI narxi va limitlari token bilan o‘lchanadi, lekin token oddiy “so‘z” emas. Input, output va context hajmini tushunish xarajatni ham, kechikishni ham boshqarishga yordam beradi.

AI atamalari: Context, Agent, Harness, Model va boshqalar
AI atamalari chalkash ko‘rinsa, ularni alohida yodlashdan ko‘ra amaliy vazifada ko‘rish osonroq. Context, prompt, model, token, agent, RAG va fine-tuning kabi so‘zlar sodda misollar bilan tartiblanadi.