Tag
Latency
Context compression. Uzun kontekst qanday ixchamlashtiriladi
Modelga ko‘proq matn yuborish har doim yaxshiroq natija bermaydi. Context compression foydali signalni saqlab, keraksiz shovqinni qisqartirish orqali narx, tezlik va aniqlik o‘rtasidagi muvozanatni yaxshilaydi.

AI billingda eng ko‘p uchraydigan 5 yashirin xarajat
AI mahsulot qurayotganda ko‘pchilik model narxiga qaraydi, lekin invoice’ni shishiradigan omillar ko‘pincha boshqa joyda bo‘ladi. Ortiqcha kontekst, retry zanjiri, noto‘g‘ri routing va uzun output lar billingni sekin, lekin muntazam ravishda oshiradi.

Pullik AI obunasi arziydimi: qachon to‘lash kerak, qachon bepul variant yetadi?
AI mahsulotlardan foydalanayotgan ko‘p odam bitta joyda to‘xtaydi: pullik reja olamanmi, yo‘qmi? Savol oddiy ko‘rinadi, lekin javob faqat narxga qarab berilmaydi. Ko‘p hollarda asosiy savol bunday bo‘lishi kerak: bu obuna menga vaqt tejayaptimi, yaxshiroq workflow berayaptimi va bepul variantda yo‘q real ustunlik bormi?
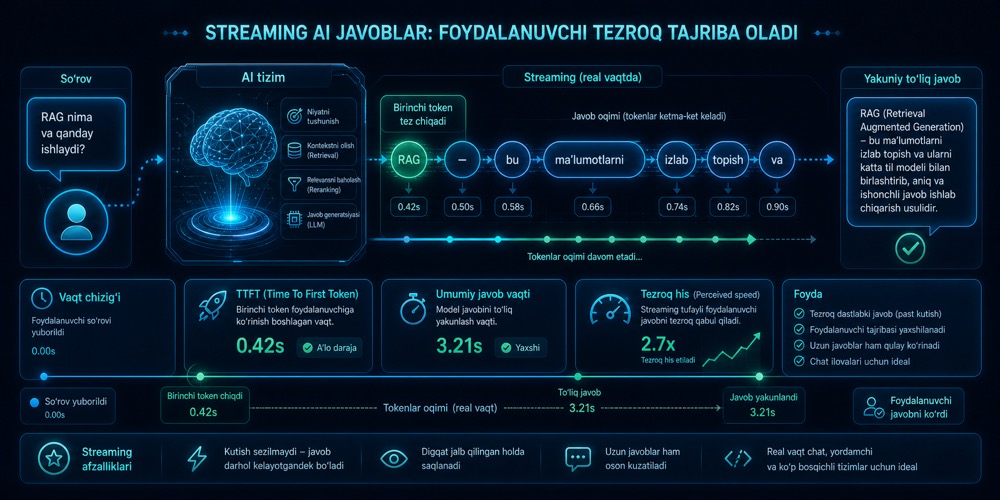
Streaming nima va u AI mahsulotda nega muhim
AI javobi tayyor bo‘lib bo‘lgach emas, yozilish jarayonida ko‘rina boshlasa, foydalanuvchi tizimni ancha tez qabul qiladi. Streaming time-to-first-tokenni pasaytirib, seziladigan kutishni kamaytiradi.
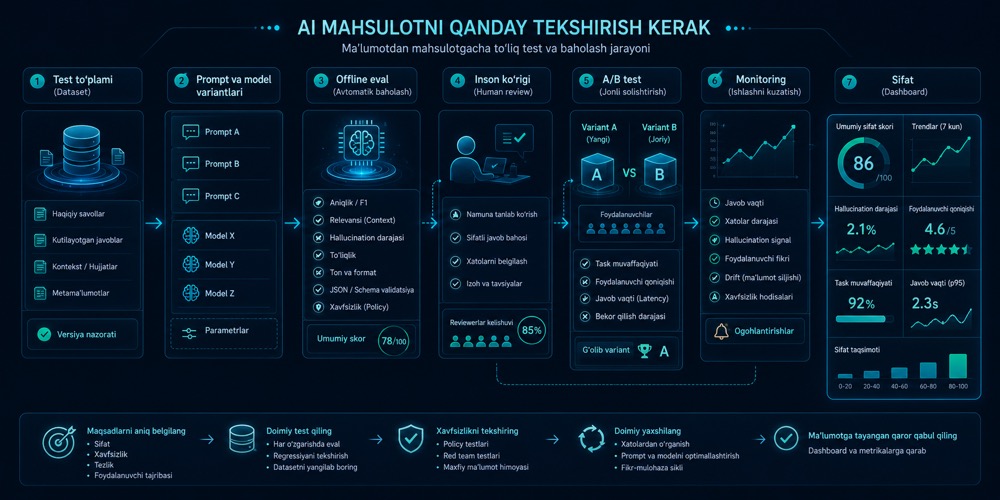
AI mahsulotni qanday tekshirish kerak
AI mahsulot sifati faqat model javobi bilan o‘lchanmaydi. Offline eval, inson review, A/B test va monitoring birga ishlaganda regressiya, xavfsizlik va foydalanuvchi tajribasi aniqroq boshqariladi.
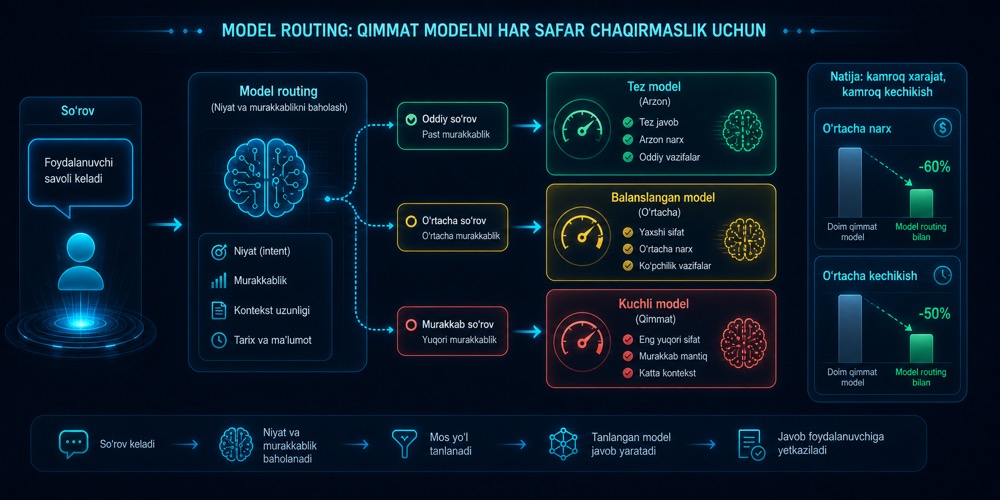
Model routing nima va qimmat modelni har safar chaqirmaslik uchun nima qilish kerak
Har bir so‘rov uchun eng katta modelni ishlatish odatda eng yaxshi arxitektura emas. Model routing vazifa murakkabligiga qarab tez, arzon va kuchli modellar o‘rtasida tanlov qilishga yordam beradi.
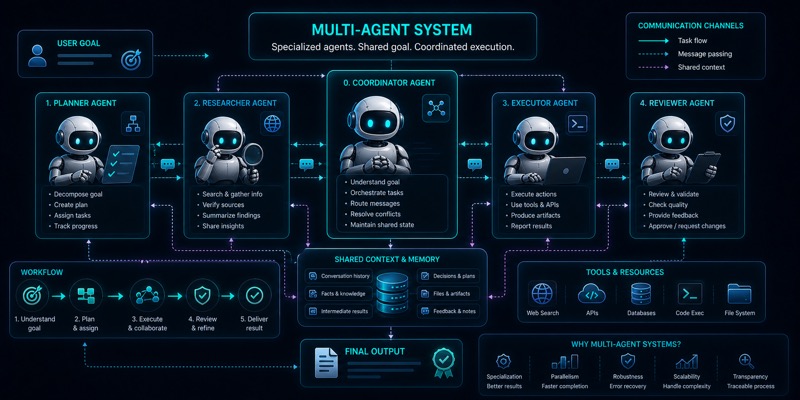
Multi-agent system qachon kerak bo‘ladi
Murakkab workflow’larda bitta agentga hamma rolni berish doim ham yaxshi natija bermaydi. Multi-agent yondashuv rollarni ajratadi, lekin koordinatsiya, kechikish va xato nuqtalarini ham ko‘paytiradi.
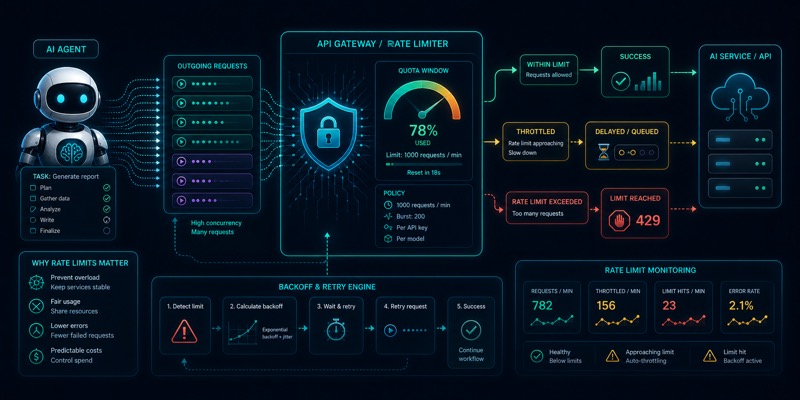
Rate limit: AI agentlar API bilan ishlaganda nima bo‘ladi
Tashqi API bilan ishlaydigan agentlar ko‘p qadam va qayta urinish sabab rate limitga tez uriladi. Bu cheklovni dizaynning bir qismi sifatida ko‘rib, cache, backoff va fallback bilan boshqarish kerak.

Async workflow: nega har bir agent real-time ishlamaydi
Ba’zi agent vazifalari darhol javob berishi shart emas. Async workflow uzoq ishlarni queue, background worker va callbacklar orqali ishonchli bajaradi.
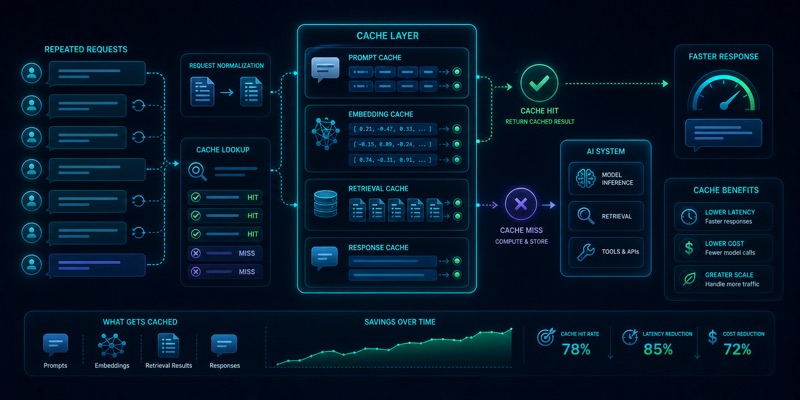
Caching: AI xarajatini qanday kamaytiradi
Bir xil prompt, retrieval yoki model javobini qayta hisoblash AI mahsulotni sekin va qimmat qiladi. Caching takror ishlarni kamaytirib, xarajat va kechikishni nazorat qilishga yordam beradi.

Observability: AI agent ichida nima bo‘layotganini qanday ko‘ramiz
AI agent xato qilganda muammo promptdami, retrieval’dami, tool call’dami yoki ruxsat qatlamidami - buni ko‘rish kerak. Observability agent ichidagi qadamlarni izchil kuzatishga yordam beradi.

Latency: AI mahsulotda nega muhim
AI mahsulotda javob sekin chiqsa, muammo faqat modelda bo‘lmasligi mumkin. Kechikish token hajmi, retrieval, tool call, cache va tashqi servislar zanjirida paydo bo‘ladi.

Context window: amalda nimani cheklaydi
Context window model bir urinishda qancha ma’lumotni ko‘ra olishini belgilaydi. Bu xotira emas; ortiqcha context narx, diqqat va kechikishga bevosita ta’sir qiladi.

AI tool use: nega modelning o‘zi yetmaydi
Kuchli model ham real ish uchun ko‘pincha tashqi vositalarga muhtoj bo‘ladi. Tool use qidiruv, API, fayl, terminal yoki database orqali modelni amaliy tizimga yaqinlashtiradi.
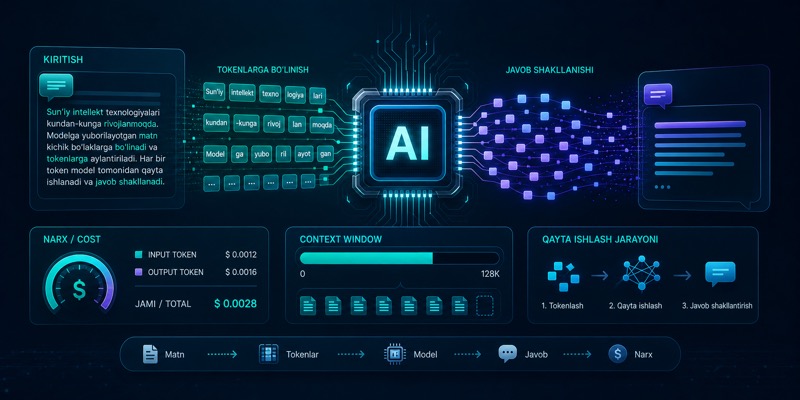
Nega AI narxi tokenga bog‘liq
AI narxi va limitlari token bilan o‘lchanadi, lekin token oddiy “so‘z” emas. Input, output va context hajmini tushunish xarajatni ham, kechikishni ham boshqarishga yordam beradi.

RAG nima va u qanday holatlarda ishlatiladi
RAG modelga tashqi manbadan topilgan dalilni berib, javobni hujjatga tayashga yordam beradi. Lekin u har doim kerak emas; qidiruv sifati, chunking va context cheklovi muhim rol o‘ynaydi.

AI atamalari: Context, Agent, Harness, Model va boshqalar
AI atamalari chalkash ko‘rinsa, ularni alohida yodlashdan ko‘ra amaliy vazifada ko‘rish osonroq. Context, prompt, model, token, agent, RAG va fine-tuning kabi so‘zlar sodda misollar bilan tartiblanadi.