Tag
Human-in-the-loop
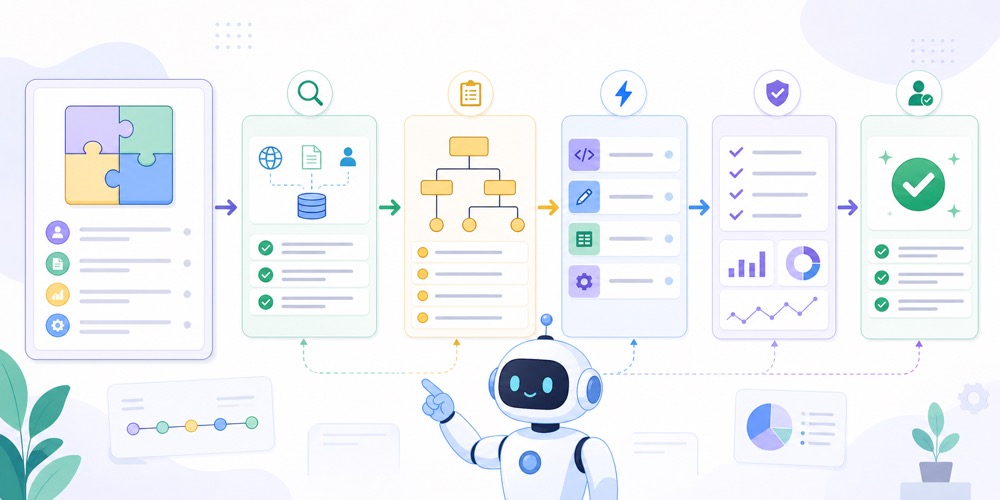
Agentga vazifani qanday bo‘linadi
Agentga “hammasini qilib ber” deyish odatda kuchli natija bermaydi. Yaxshi task decomposition maqsadni bosqichlarga ajratib, qayerda tekshiruv, qayerda approval va qayerda action bo‘lishini aniq qiladi.
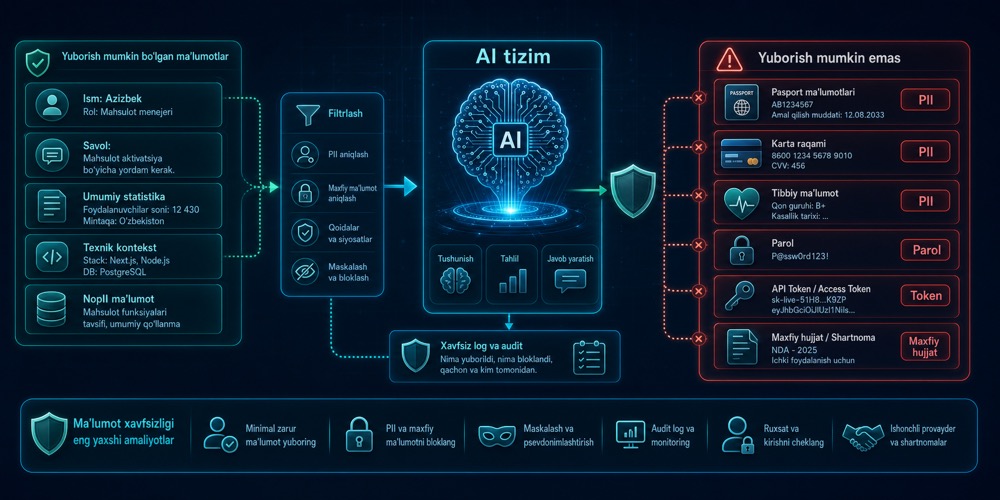
PII va maxfiy ma’lumotlar: AI tizimga nimani yubormaslik kerak
AI tizimga foydali context yuborish kerak, lekin ortiqcha va maxfiy ma’lumot yuborish katta risk tug‘diradi. PII, parol, token va yopiq hujjatlar alohida nazorat va filtrlash talab qiladi.
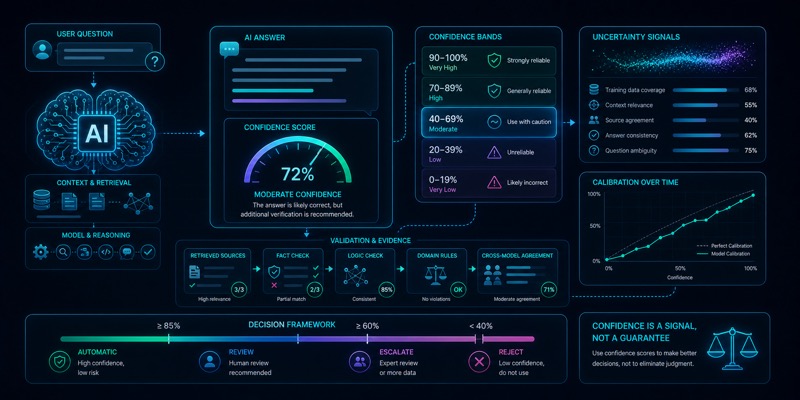
Confidence score nima va unga qanchalik ishonish mumkin
Confidence score foydali signal bo‘lishi mumkin, lekin uni haqiqat mezoni deb qabul qilish xavfli. Ishonch darajasi eval, validation va inson nazorati bilan birga talqin qilinganda ancha foydaliroq bo‘ladi.

Guardrails: agentga qayerda to‘siq qo‘yiladi
Guardrails agentni foydali chegarada ushlab turadi: prompt, tool, permission, output va inson approvali darajasida xavfli harakatlar to‘xtatiladi.

Tool registry va agent tanlovi
Agentda tool ko‘p bo‘lsa, ularni promptga sanab qo‘yish yetmaydi. Tool registry har bir imkoniyatni tartiblaydi, tavsiflaydi va tanlovni xavfsizroq qiladi.
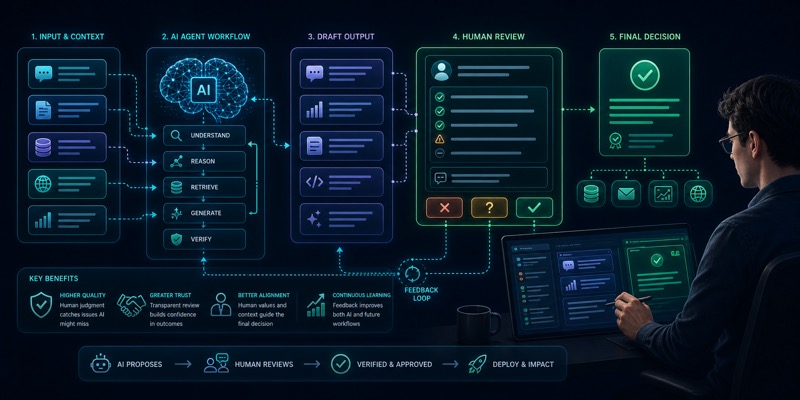
Human-in-the-loop tushunchasi va u qachon kerak bo'ladi
AI mahsulotda hamma qarorni avtomatlashtirish shart emas. Human-in-the-loop yondashuvi xavfli yoki noaniq qadamlarni inson tasdig‘i bilan bog‘lab, sifat va ishonchni oshiradi.
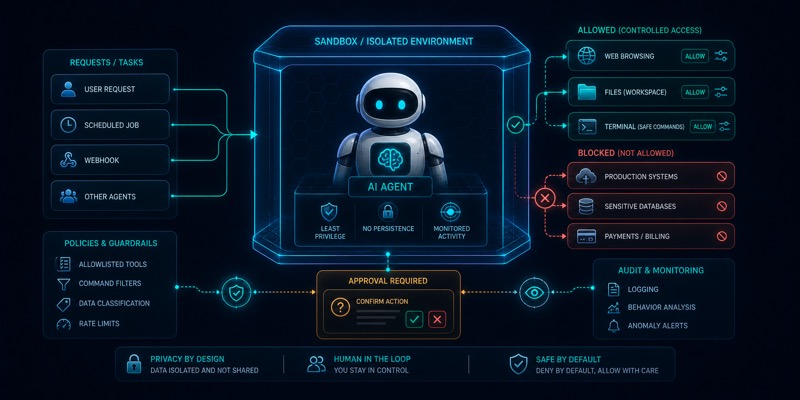
Permission va sandbox. AI agentga qancha erkinlik berish kerak
AI agentga qancha ko‘p erkinlik berilsa, xato narxi ham shuncha oshadi. Permission va sandbox agentning qaysi vosita, fayl, API yoki amalga tegishi mumkinligini chegaralaydi.